BERT相关——(8)BERT-based Model代码分析
BERT相关——(8)BERT-based Model代码分析
引言
上一篇提到如何利用BERT开展下游任务,以及fine tuning的方法。BertModel的输出了每个句子每个词的embedding,我们在Bert模型后面接上不同的任务就可以构建不同的模型。
HuggingFace的transformers库封装好了各个任务最简易的API,帮助我们快速开始。
实现了以下几个任务:
- BertForPreTraining
- BertForSequenceClassification
- BertForMultiChoice
- BertForTokenClassification
- BertForQuestionAnswering
如果我们想在其中增加一些模块,比如LSTM、CRF等优化模型,我们可以仿造这些封装好的API的写法,在这篇博客的最后将总结一下如何基于Bert模型进行扩展完成NLP任务。
下面来分析各个API的源码。
BertPreTrainedModel基类
HuggingFace的transformers库中基于 BERT 的模型都是基于BertPreTrainedModel这一抽象基类的,而后者则基于一个更大的基类PreTrainedModel。这里我们关注BertPreTrainedModel的功能:
BertPreTrainedModel用于初始化模型权重,同时维护继承自PreTrainedModel的一些标记身份或者加载模型时的类变量。
class BertPreTrainedModel(PreTrainedModel): |
下面,首先从预训练模型开始分析。
BertForPreTraining相关
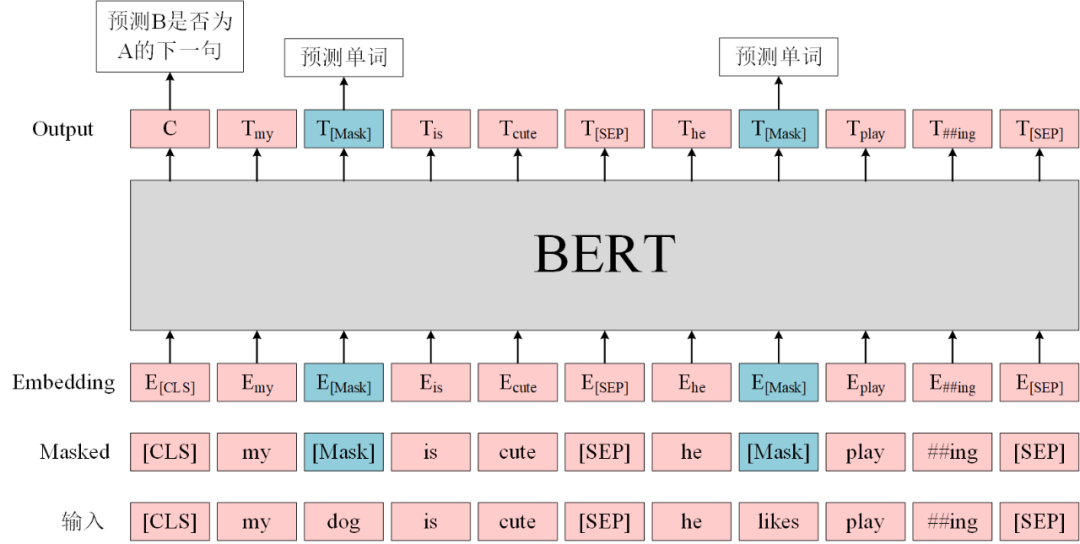
原始Bert的预训练模型包括两个训练任务:
- Masked Language Model(MLM):在句子中随机用
[MASK]替换一部分单词,然后将句子传入 BERT 中得到每一个单词的embedding,最终用[MASK]的embedding预测该位置的正确单词,这一任务旨在训练模型根据上下文理解单词的意思; - Next Sentence Prediction(NSP):将句子对 A 和 B 输入 BERT,使用
[CLS]的embedding进行预测 B 是否 A 的下一句,这一任务旨在训练模型理解预测句子间的关系。
需求分析
根据上面两个任务,显然我们有以下几个需求需要满足:
初始化一个BertModel;
- 实现分别完成这两个训练任务的代码;(如果我们只想训练其中一个训练任务怎么办呢?->完成单个训练任务的模型)
- 训练的loss function;
模型保存;
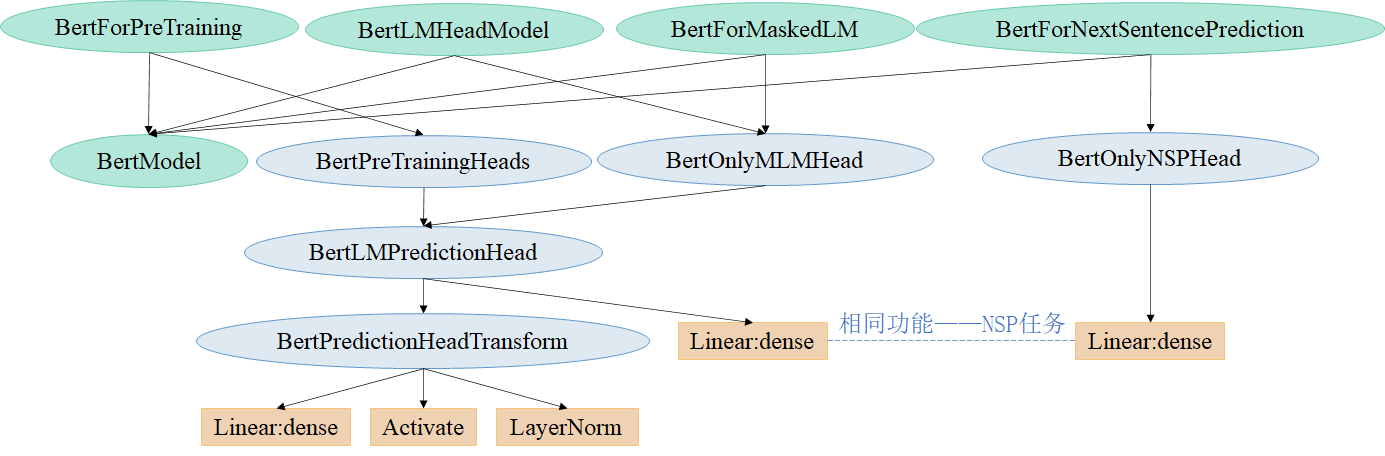
BertForPreTraining相关类的实现逻辑(HuggingFace)
HuggingFace的transformers库提供了对两个目标都进行预训练、以及只对其中一个任务进行预训练的Bert预训练模型:
- BertForPreTraining:进行MLM和NSP两个任务的预训练;
- BertForMaskedLM:只进行 MLM 任务的预训练;
- BertLMHeadModel:这个和上一个的区别在于,这一模型是作为 decoder 运行的版本;
- BertForNextSentencePrediction:只进行 NSP 任务的预训练。
实现逻辑封装如下图所示:
BertForPreTraining
首先是完成两个训练目标的预训练模型BertForPreTraining。
调用案例
from transformers import BertTokenizer, BertForPreTraining |
源码
|
源码分析
BertForPreTraining类包括BertModel、BertPreTrainingHeads、loss计算三个主要的部分。
BertModel:BertModel在上一篇博客中已经详细分析了(其中,add_pooling_layer=True为默认值,BertModel中会加入BertPooler层,即会提取[CLS]对应的输出用于 NSP 任务);BertPreTrainingHeads:负责MLM和NSP任务的预测模块(下面继续分析);loss计算:包括MLM任务的loss和NSP任务的loss,两个任务的本质都是分类,所以选择CrossEntropyLoss作为损失函数,直接将两部分loss相加作为最终的loss。- labels:形状为[batch_size, seq_length] ,代表 MLM 任务的标签,注意这里对于原本未被遮盖的词设置为 -100,被遮盖词才会有它们对应的 id,和数据预处理的时候是反过来的。
- 例如,原始句子是I want to [MASK] an apple,把单词eat给遮住了输入模型,对应的label设置为[-100, -100, -100, 【eat对应的id】, -100, -100];
- 为什么要设置为 -100 而不是其他数?因为torch.nn.CrossEntropyLoss默认的ignore_index=-100,也就是说对于标签为 100 的类别输入不会计算 loss。
- next_sentence_label:0 和 1 的二分类标签,0表示两个句子是上下句关系,1表示两个句子是随机拼接在一起的。
- labels:形状为[batch_size, seq_length] ,代表 MLM 任务的标签,注意这里对于原本未被遮盖的词设置为 -100,被遮盖词才会有它们对应的 id,和数据预处理的时候是反过来的。
BertPreTrainingHeads-用于MLM任务和NSP任务
源码
class BertPreTrainingHeads(nn.Module): |
源码分析
BertPreTrainingHeads包括BertLMPredictionHead用于MLM任务,一个线性层nn.Linear用于NSP任务。
注意:此处用于NSP任务的线性层nn.Linear与下文中BertOnlyNSPHead类(该类本质也是一层nn.Linear,只是进行了封装)功能相同。
BertLMPredictionHead-用于MLM任务
源码
class BertLMPredictionHead(nn.Module): |
源码分析
用于预测[MASK]位置的输出在每个词作为类别的分类输出,注意到:
- 该类重新初始化了一个全 0 向量作为预测权重的
bias; - 该类的输出形状为[batch_size, seq_length, vocab_size],即预测每个句子每个词是什么类别的概率值(注意这里没有做 softmax,因为CrossEntropyLoss内部包括了softmax的计算操作);
BertPredictionHeadTransform,用来完成一些线性变换:
BertPredictionHeadTransform-用于MLM任务线性变换
class BertPredictionHeadTransform(nn.Module): |
源码分析
对输入的embedding进行线性变换、激活和层归一化。
BertForMaskedLM
BertForMaskedLM只完成MLM任务,事实上后续的RoBERTa、ALBERT、spanBERT等模型都移去了NSP任务(消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高)。
调用案例
from transformers import BertTokenizer, BertForMaskedLM |
源码
|
BertOnlyMLMHead-封装BertLMPredictionHead
class BertOnlyMLMHead(nn.Module): |
源码分析
仍然是分三步:
- 初始化BertModel;
- 完成MLM任务;
- loss计算:显然只有MLM的loss。
BertLMHeadModel——next token任务(deocder版本)
与上面的BertForMaskedLM模型不同,BertLMHeadModel模型是decoder版本,也就是只能利用上文而不能利用下文,任务修改为next token prediction。
调用案例
from transformers import BertTokenizer, BertLMHeadModel, BertConfig |
源码
|
源码分析
仍然是分三步:
- 初始化BertModel;
- 完成LM任务:注意这里做的是下一个token预测的任务;
- loss计算:计算下一个token预测结果的loss。
BertForNextSentencePrediction
只做NSP任务。
调用案例
from transformers import BertTokenizer, BertForNextSentencePrediction |
源码
|
BertOnlyNSPHead
|
源码分析
仍然是分三步:
- 初始化BertModel;
- 完成NSP任务;
- loss计算:显然只有NSP的loss。
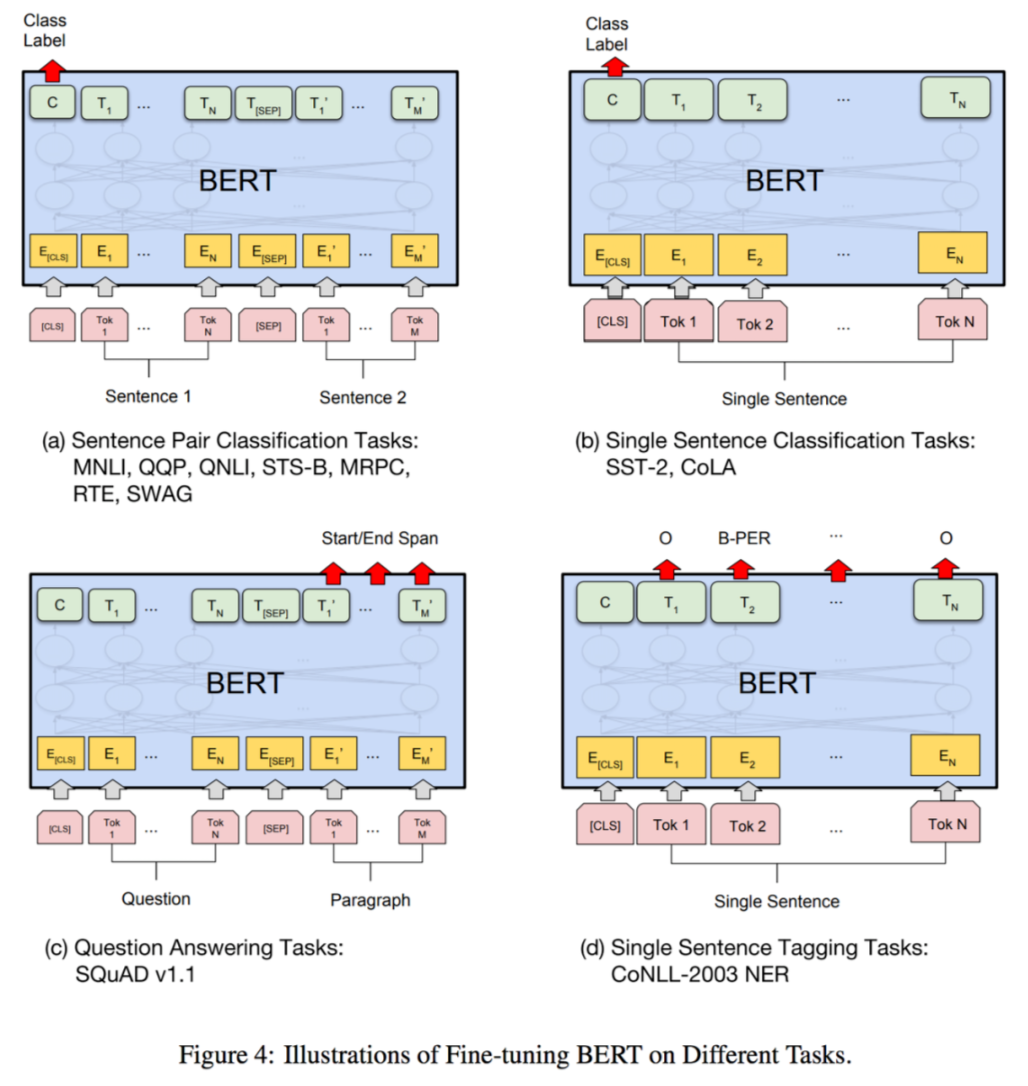
接下来介绍HuggingFace-Transformers库中实现的四种 Fine-tune 模型,基本都是分类任务,与上一篇博客相对应,不包括seq2seq模型。
one class-BertForSequenceClassificationone class-BertForMultipleChoiceclass for each token-BertForTokenClassificationcopy from input-BertForQuestionAnswering
one class-BertForSequenceClassification
用于句子分类(也可以是回归)任务,比如 GLUE benchmark 的各个任务。
输入为句子(对),输出为单个分类标签。
调用案例
from transformers.models.bert.tokenization_bert import BertTokenizer |
源码
|
源码分析
分三步:
- 初始化BertModel(有 pooling);
- 分类任务:过一个 dropout,接一个线性层输出分类;
- loss计算:分类任务loss。
在前向传播时,需要传入labels输入:
如果初始化的num_labels=1,默认为回归任务,使用 MSELoss;
否则认为是分类任务。
one class-BertForMultipleChoice
用于多项选择,如 RocStories/SWAG 任务。
输入为一组分次输入的句子,输出为选择某一句子的单个标签。
结构上与句子分类相似,不过线性层输出维度为 1,即每次需要将每个样本的多个句子的输出拼接起来作为每个样本的预测分数。
实际上,具体操作时是把每个 batch 的多个句子一同放入的,所以一次处理的输入为[batch_size, num_choices]数量的句子,因此相同 batch 大小时,比句子分类等任务需要更多的显存,在训练时需要小心。
调用示例
from transformers.models.bert.tokenization_bert import BertTokenizer |
源码
|
源码分析
分三步:
- 初始化BertModel(有 pooling);
- 分类任务:过一个 dropout,接一个线性层输出分类;
- loss计算:分类任务loss。
- 在前向传播时,需要传入labels输入:[batch_size,num_choices]
class for each token-BertForTokenClassification
用于序列标注(词分类),如 NER 任务。
输入为单个句子文本,输出为每个 token 对应的类别标签。
调用案例
from transformers import BertForTokenClassification, BertTokenizer |
源码
|
源码分析
分三步:
- 初始化BertModel,由于需要用到每个 token对应的输出而不只是某几个,所以这里的BertModel不用加入 pooling 层(
add_pooling_layer=False),同时,这里将_keys_to_ignore_on_load_unexpected这一个类参数设置为[r"pooler"],也就是在加载模型时对于出现不需要的权重不发生报错。 - 分类任务:过一个 dropout,接一个线性层输出分类;
- loss计算:每个词的分类任务loss。
- 在前向传播时,需要传入labels输入:[batch_size,num_labels]
copy from input-BertForQuestionAnswering
用于解决问答任务,例如 SQuAD 任务。
输入为问题 +(对于 BERT 只能是一个)回答组成的句子对,输出为起始位置\(s\)和结束位置\(e\)用于标出回答中的具体文本。
这里需要两个输出,即对起始位置的预测和对结束位置的预测,两个输出的长度都和句子长度一样,分别选择最大的预测值对应的下标作为预测的位置。
调用案例
from transformers import AutoTokenizer, AutoModelForQuestionAnswering |
源码
|
源码分析
分三步:
- 初始化BertModel(无 pooling);
- 分类任务:过一个 dropout,接一个线性层输出分类;
- loss计算:预测答案起始位置loss和预测答案终止位置的loss,本质都是分类任务。
- 在前向传播时,需要传入start_positions、end_positions;
- 对超出句子长度的非法 label,会将其压缩(torch.clamp_)到合理范围。
使用Bert模型方法总结
可以看到上面的源码分析,总结一下我们都可以分成三步走:
- 初始化BertModel,注意需不需要加pooler层,用参数
add_pooling_layer控制,默认为True; - 根据任务自行定制对BertModel输出进行处理的层,比如Dropout、Linear,还可以再接上一些复杂模型,如LSTM、CNN等,此时需要注意层之间的输入、输出维度;
- loss计算,同样根据任务进行定义,forward函数往往需要传入ground truth。
再补充第0步为继承BertPreTrainedModel类,以及第4步输出需要的内容,于是我们可以得到下面这个Bert-based模型改写框架:
class BertForQuestionAnswering(BertPreTrainedModel): |